Top Prompt Engineering Examples to Boost AI Results
Discover 8 prompt engineering examples to improve AI responses. Learn practical techniques with these effective prompt engineering examples.
Unlocking AI's Potential Through Prompt Engineering
Want better results from large language models (LLMs)? This listicle provides eight powerful prompt engineering examples to improve the accuracy, relevance, and creativity of your AI outputs. Learn practical techniques like the Chain-of-Thought prompt and the CRISPE Framework to enhance your interactions with LLMs like ChatGPT, Gemini, and other AI platforms. These prompt engineering examples will help you unlock new possibilities, whether you're a seasoned AI professional or just starting out. Explore these techniques and transform your LLM outputs.
1. The Chain-of-Thought Prompt
Chain-of-Thought (CoT) prompting is a powerful technique in prompt engineering that encourages large language models (LLMs) to break down complex problems into a series of smaller, logical steps before arriving at a final answer. This method mimics the way humans reason, leading to significantly improved performance on tasks requiring multi-step analysis, logical deduction, or mathematical problem-solving. Instead of simply requesting the answer, you guide the LLM to "think step by step," providing a more structured and reliable path to the solution.
This approach is particularly effective when dealing with mathematical and logical problems, where a direct answer might be difficult for the LLM to produce accurately. By explicitly asking the model to articulate its reasoning process, using phrases like "Let's work through this systematically" or "Think step by step," you enhance its ability to handle complex operations and reduce the likelihood of errors. This method deserves its place in any prompt engineering listicle because it offers a significant improvement in accuracy and transparency for a wide range of complex tasks. Learn more about The Chain-of-Thought Prompt.
Features of CoT Prompting:
- Explicitly instructs the model to 'think step by step'.
- Uses phrases like 'Let's work through this systematically', 'Let's break this down', or 'Let's solve this step-by-step'.
- Can include examples demonstrating the step-by-step reasoning process, guiding the LLM's behavior.
- Especially effective for mathematical and logical problems, although its applications extend to other complex reasoning tasks.
Pros:
- Improved Accuracy: Dramatically increases accuracy on complex reasoning tasks compared to standard prompting methods.
- Transparency: Provides valuable insight into the model's decision-making process, making it easier to understand how it arrived at a particular conclusion.
- Error Detection: The step-by-step breakdown allows humans to identify errors in the model's reasoning, facilitating debugging and improvement.
- Reduced Hallucinations: By enforcing logical consistency through step-by-step reasoning, CoT can help minimize instances where the LLM generates factually incorrect or nonsensical output.
Cons:
- Increased Token Usage: The more detailed responses generated by CoT prompting consume more tokens, potentially increasing the cost of using the LLM.
- Verbosity: For simpler questions, CoT can be unnecessarily verbose, adding extra steps that don't contribute significantly to the solution.
- Potential for Initial Errors: If the model's initial reasoning path is flawed, the subsequent steps may also be incorrect, leading to a final answer that is still wrong despite the detailed breakdown.
Examples of CoT Prompts:
- OpenAI's research demonstrates CoT improving performance on math word problems by a significant margin (over 30% in some cases). Google's use of CoT in PaLM highlights its effectiveness for various complex reasoning tasks.
- A simple prompt like "Think step by step. What is the solution to 13×27−15×4?" demonstrates the core principle of CoT. A more advanced example would include a few-shot demonstration with a similar problem worked out step by step.
Tips for Effective CoT Prompting:
- Provide Examples: Include one or more examples of step-by-step reasoning in your prompt to guide the LLM.
- Combine with Few-Shot Learning: For maximum impact, integrate CoT with few-shot learning, providing a few examples of the task with detailed solutions.
- Explicitly Request Reasoning: Clearly state that you want to see the reasoning process, not just the final answer.
- Use Specific Phrasing: Utilize phrases like 'Let's break this down' or 'Let's solve this step-by-step' to encourage the desired behavior.
Chain-of-Thought prompting is a valuable tool for anyone working with LLMs, including AI professionals, software engineers, tech-savvy entrepreneurs, and digital marketers. It's a crucial technique for extracting reliable and transparent results from LLMs, particularly when dealing with complex or multi-step problems.
Get started with your lifetime license
Enjoy unlimited conversations with MultitaskAI and unlock the full potential of cutting-edge language models—all with a one-time lifetime license.
Demo
Free
Try the full MultitaskAI experience with all features unlocked. Perfect for testing before you buy.
- Full feature access
- All AI model integrations
- Split-screen multitasking
- File uploads and parsing
- Custom agents and prompts
- Data is not saved between sessions
Lifetime License
Most Popular€99€149
One-time purchase for unlimited access, lifetime updates, and complete data control.
- Everything in Free
- Data persistence across sessions
- MultitaskAI Cloud sync
- Cross-device synchronization
- 5 device activations
- Lifetime updates
- Self-hosting option
- Priority support
Loved by users worldwide
See what our community says about their MultitaskAI experience.
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
2. Few-Shot Prompting Template
Few-shot prompting is a powerful prompt engineering technique that provides a practical way to guide AI models toward desired outputs. Instead of relying on lengthy, explicit instructions, you provide the model with a few examples of the input-output pattern you're looking for. This "learning by example" approach helps the AI understand nuances in format, style, and content that can be difficult to articulate directly. It's like showing, not telling, the AI what you want. This method makes it easier to steer the model’s responses and achieve greater control over the generated content, making it a valuable tool in your prompt engineering arsenal.
Few-shot prompting typically involves presenting 2-5 clear examples, each demonstrating the desired input and its corresponding output. Maintaining consistent formatting across these examples is crucial, as it helps the model recognize the pattern and apply it to the subsequent prompt. This technique often concludes with a new input, formatted identically to the preceding examples, prompting the AI to generate an output following the established pattern. Few-shot prompting can also be combined with other prompt engineering techniques for even finer control. This approach earns its place on this list due to its effectiveness, versatility, and ease of implementation across various tasks and AI models.
Features:
- Contains 2-5 clear examples of input and desired output.
- Maintains consistent formatting across examples.
- Often ends with the new input following the same pattern.
- Can be combined with other prompting techniques.
Pros:
- Reduces the need for lengthy explanations.
- Dramatically improves output consistency.
- Works well across different types of tasks and domains.
- Helps models understand nuanced requirements that are difficult to explain.
Cons:
- Consumes more tokens than direct prompting.
- Examples may inadvertently introduce biases.
- Effectiveness depends on the quality and representativeness of examples.
Examples of Successful Implementation:
Sentiment Classification: Input: "This movie is fantastic!" Output: Positive
Input: "I hated every minute of it." Output: Negative
Input: "It was an okay film." Output: Neutral
Input: "This restaurant is amazing!" Output:
Language Translation: English: Hello Spanish: Hola
English: Goodbye Spanish: Adiós
English: Thank you Spanish: Gracias
English: Good morning Spanish:
Content Summarization: Article: [Long article text...] Summary: [Short summary of the article]
Article: [Another long article text...] Summary: [Another short summary]
Article: [Yet another long article text...] Summary: [Another short summary]
Article: [New article text...] Summary:
Tips for Effective Few-Shot Prompting:
- Diversity and Representativeness: Use diverse examples that cover potential edge cases the model might encounter.
- Consistent Formatting: Maintain strict consistency in formatting between examples and the final query. This helps the model recognize the pattern.
- Placement of Examples: For optimal results, place the examples immediately before your actual query within the prompt.
- Optimal Number of Examples: 2-5 examples are generally sufficient. More isn't always better due to context limitations within the AI model.
- Clear Delineation: Clearly separate examples using separators like lines, numbering, or distinct labels.
When and Why to Use Few-Shot Prompting:
Use few-shot prompting when you need specific output formatting, style, or a level of detail that's hard to describe with instructions alone. It's particularly beneficial when dealing with nuanced tasks or creative applications where demonstrating the desired outcome is more effective than explaining it. This approach has been popularized by research from Tom Brown and OpenAI researchers (Language Models are Few-Shot Learners) and is featured in Anthropic's Claude documentation on effective prompting strategies. This technique is a valuable tool for prompt engineering examples, offering a practical and effective way to improve output quality and consistency.
3. Role-Based Prompting Framework
Role-based prompting is a powerful prompt engineering technique that significantly enhances the quality and relevance of outputs from large language models (LLMs). This method involves instructing the AI to "act as" a specific persona, role, or identity, thereby framing its responses from that perspective. This is a key example of prompt engineering, demonstrating how a simple adjustment to your prompt can drastically improve results. By assigning a role, you leverage the LLM's ability to mimic different styles and areas of expertise, making it a valuable tool for diverse applications.
How it Works:
This prompt engineering example works by setting the context for the LLM. Instead of simply asking a question, you provide the model with a specific role and, optionally, a detailed description of that role's characteristics, expertise, experience level, goals, and even stylistic preferences. This framework helps the LLM focus its knowledge base and generate outputs consistent with the assigned persona. For instance, instead of asking "What are the benefits of intermittent fasting?", you might prompt, "Act as a registered dietitian and explain the benefits of intermittent fasting to a client considering this dietary approach." This nuanced approach yields more tailored and informative responses.
Features of Role-Based Prompting:
- Explicit Role Assignment: Prompts typically begin with phrases like "Act as a [role]" or "You are a [role]".
- Role Description: Often includes details about the role's characteristics, expertise, credentials, experience level, and stylistic preferences.
- Goal Orientation: Can specify the role's goals or principles, guiding the response toward a particular objective.
Examples of Successful Implementation:
- Software Development: "Act as a senior Python developer with 15 years of experience and explain the advantages of using Django REST Framework for building APIs."
- Medical Content Review: "You are a board-certified physician specializing in cardiology. Explain the risks and benefits of angioplasty to a patient."
- Writing Assistance: "You are a Pulitzer Prize-winning journalist known for clarity and conciseness. Write a short article about the impact of climate change on coastal communities." This prompt engineering example leverages the assumed knowledge and writing style associated with a prize-winning journalist.
- Marketing: "You are a marketing consultant specializing in social media strategy for SaaS startups. Develop a content calendar for the next quarter, focusing on lead generation."
Pros:
- Domain-Specific Knowledge: Elicits specialized terminology and insights, providing more authoritative responses.
- Consistent Tone and Perspective: Maintains a uniform voice and approach throughout the interaction.
- Focused Responses: Helps the model concentrate on relevant aspects of a problem or topic.
- Enhanced Creativity: Can spark more imaginative and engaging outputs, particularly for creative writing tasks.
Cons:
- Overconfidence/Jargon: May produce overly confident assertions or use technical jargon that obscures meaning for a general audience.
- Stereotypical Representations: Can sometimes lead to stereotypical or biased responses if the model's training data reflects societal biases.
- Variable Effectiveness: The success of this technique depends on the model's understanding of the specified role.
Tips for Effective Role-Based Prompting:
- Specificity: Be precise about the role's qualifications, expertise, and experience level.
- Goal Clarity: Clearly define the purpose or goal the role should focus on achieving.
- Audience Awareness: Specify the intended audience for the response.
- Task Alignment: Ensure the task instructions align with the role's expertise.
- Methodology (Technical Roles): For technical roles, specify methodologies or frameworks the role should utilize.
Why Role-Based Prompting Matters:
This prompt engineering example is crucial because it significantly improves the control and precision of LLM interactions. By defining a specific role, you guide the LLM's output, making it more relevant, accurate, and tailored to your needs. This method is particularly valuable for complex or specialized tasks where domain expertise is crucial. It helps avoid generic or irrelevant responses, making it a powerful tool for anyone seeking to maximize the potential of LLMs.
4. The CRISPE Framework Prompt
The CRISPE Framework Prompt is a powerful technique for prompt engineering, offering a structured approach to crafting effective prompts for AI models. This method helps ensure clarity, reduces ambiguity, and improves the alignment of AI-generated output with your desired outcome. It deserves a place on this list of prompt engineering examples because it provides a comprehensive and adaptable strategy for tackling a wide range of tasks, from simple content generation to complex problem-solving. This makes it particularly valuable for prompt engineering examples showcasing best practices.
CRISPE stands for Capacity and Role, Insight, Statement, Persona, and Execution. Each component plays a specific role in constructing a well-defined prompt:
- Capacity and Role: Defines the AI's expertise. Are you asking it to act as a marketing consultant, a poet, a programmer, or something else? Clearly defining the AI's role sets the stage for the entire interaction. For example, "Act as a seasoned marketing consultant..."
- Insight: This section provides the AI with necessary background information, context, or constraints. This could include data, facts, assumptions, or specific requirements. For complex tasks, providing detailed insight is crucial for accurate and relevant responses. For instance, "considering current market trends in sustainable products..."
- Statement: This is the core of your prompt – the specific task or request you want the AI to perform. Be clear and concise in stating what you want the AI to generate. For example, "develop three innovative marketing campaign ideas..."
- Persona: Specifying the intended audience or perspective shapes the tone and style of the AI's output. Should the AI respond as a friend, a formal expert, or a specific demographic? This is especially important for content creation tasks. For instance, "targeting environmentally conscious millennials..."
- Execution: This section details the format, style, tone, length, and other output parameters. This ensures consistency and helps you receive the output in the desired format. Examples include: "Provide the output in a bulleted list, including a tagline, target audience, and key channels for each campaign idea."
Examples of Successful Implementation:
- Marketing: Using CRISPE to generate targeted campaign ideas. For example, you could ask the AI to act as a marketing consultant (Capacity and Role), provide market research data (Insight), request campaign ideas (Statement), specify the target audience (Persona), and request a structured output with taglines and channel strategies (Execution).
- Educational Content Development: Constructing prompts for educational materials using all CRISPE elements. You could ask the AI to act as a history professor (Capacity and Role), provide historical context (Insight), request a lesson plan on a specific topic (Statement), specify the target student age group (Persona), and request the output as a structured outline with learning objectives and activities (Execution).
- Business Analysis: Using CRISPE to analyze data and provide insights. Define the AI as a business analyst (Capacity and Role), provide the relevant data (Insight), ask for specific insights or recommendations (Statement), specify the stakeholders who will receive the analysis (Persona), and request the output in a formal report format (Execution).
Actionable Tips:
- Not all elements are always necessary. Use what's relevant to your specific task.
- Start with the Statement (task) and build the other elements around it.
- Be specific about Execution parameters for consistent formatting.
- Consider your audience when defining the Persona.
- For complex tasks, be more detailed in the Insight section.
Pros:
- Creates highly structured, comprehensive prompts
- Reduces ambiguity and improves output alignment
- Adaptable to virtually any task or domain
- Helps address common failure points in AI interactions
Cons:
- Can be overly verbose for simple requests
- Requires more initial effort to construct prompts
- May use more tokens than necessary for straightforward tasks
Learn more about The CRISPE Framework Prompt
The CRISPE Framework is a valuable tool for anyone working with AI models. By providing a structured approach to prompt engineering, it empowers users to generate more accurate, relevant, and consistent results. This framework is particularly useful for AI professionals, developers, software engineers, tech-savvy entrepreneurs, ChatGPT and LLM users, including those utilizing platforms like Anthropic, Google Gemini, and for digital marketers seeking optimized content generation.
No spam, no nonsense. Pinky promise.
5. Zero-Shot ReAct Prompt
Zero-Shot ReAct prompts represent a significant advancement in prompt engineering examples, offering a powerful way to tackle complex problems using Large Language Models (LLMs). ReAct, short for "Reasoning + Acting," guides the AI through an iterative process of thinking, acting, and observing. Instead of providing explicit examples (as in few-shot prompting), ReAct works by outlining the process of problem-solving itself, making it incredibly versatile for a wide range of applications. This method mimics human problem-solving approaches, allowing the AI to decompose complex tasks into smaller, manageable steps.
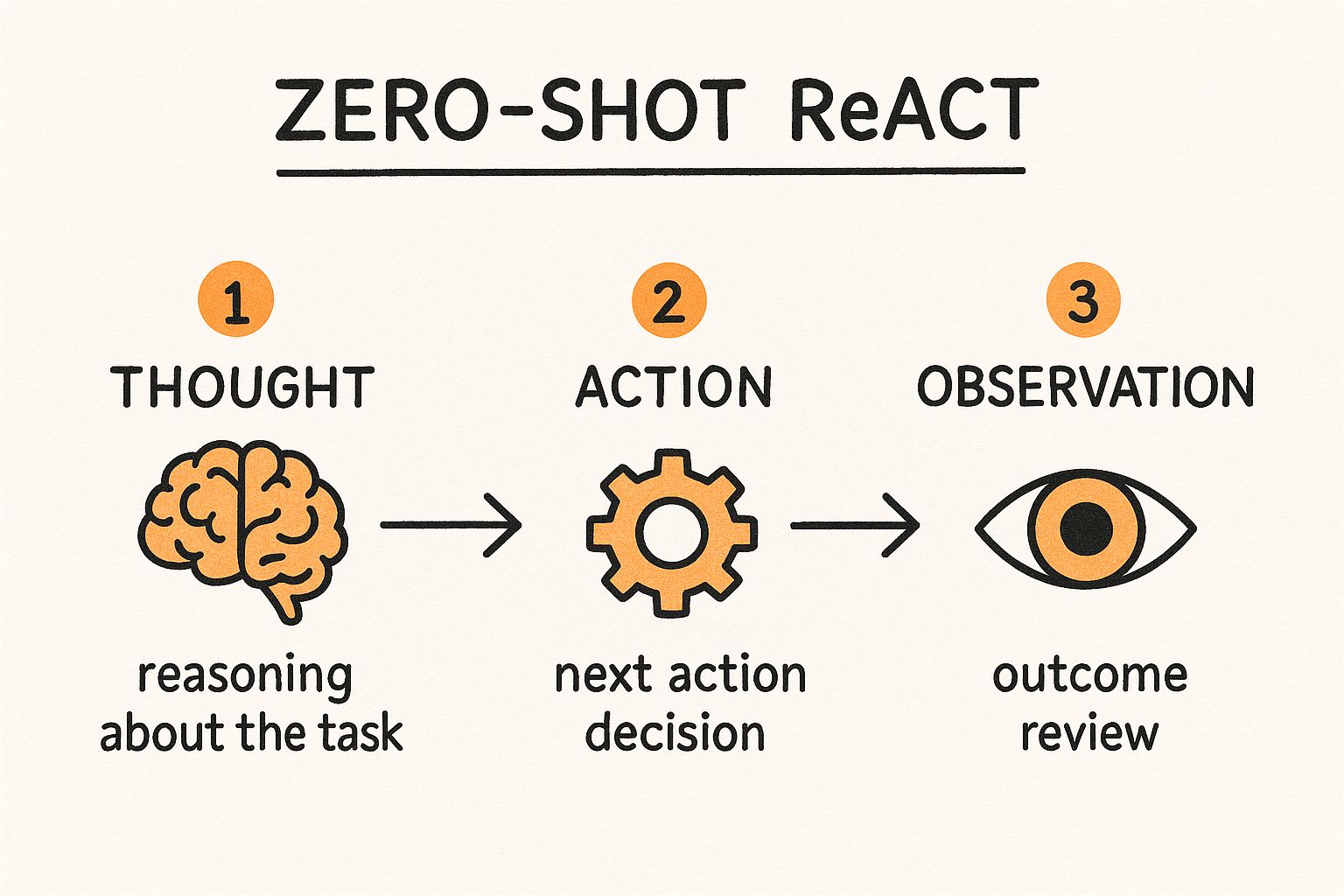
The infographic visualizes the core ReAct loop: Thought, Action, Observation. It begins with the AI formulating a "Thought" – its reasoning about the problem based on the current information. This leads to an "Action" – a decision about the next step, such as formulating a search query or requesting specific data. The resulting "Observation" provides new information, feeding back into the Thought process for the next iteration. This continues until a solution is reached or a predefined stopping condition is met. The cyclical nature highlighted in the infographic emphasizes the iterative and dynamic nature of the ReAct framework.
This approach offers several key features. It explicitly structures responses into Thought, Action, and Observation cycles, enabling transparency and auditability. It functions in a zero-shot manner, meaning it doesn't require examples to understand the task. Furthermore, it excels at multi-step reasoning and problems involving information gathering.
Examples of Successful Implementation:
- Google DeepMind: Has explored ReAct for complex reasoning tasks, demonstrating its ability to outperform traditional prompting methods.
- Information Retrieval Systems: ReAct can be used to decompose complex search queries into a series of smaller, more targeted queries, leading to more relevant results.
- Technical Troubleshooting: Multi-step problem-solving systems leverage ReAct to diagnose and resolve technical issues by iteratively gathering information and testing potential solutions.
Pros:
- Dramatically improved performance on complex reasoning tasks.
- Transparent, auditable decision processes.
- Reduction in hallucinations by grounding reasoning in observations.
- Excellent for tasks requiring information gathering and synthesis.
Cons:
- Can significantly increase token usage.
- Might be overkill for straightforward questions.
- May require refinement for specific domains.
Tips for Effective ReAct Prompts:
- Clearly Define Actions: Explicitly list the actions the AI can take (e.g., "search the web," "access the database," "ask a clarifying question").
- Specify Format: Provide clear instructions on the expected format for each step (e.g., "Thought: ...", "Action: ...", "Observation: ...").
- Limit Steps: For complex tasks, set a maximum number of iterations to prevent infinite loops.
- Define Termination Conditions: Guide the AI on when to conclude the reasoning process (e.g., "when you have a solution" or "after 5 steps").
- Encourage Thoroughness: Prompt the model to provide detailed reasoning in its "Thought" sections.
When and Why to Use ReAct:
Zero-Shot ReAct prompts are ideal for complex problem-solving scenarios, especially those requiring information retrieval, multi-step reasoning, or branching decision paths. When simpler prompting techniques fall short, ReAct offers a more robust and systematic approach, though the increased token usage should be considered. This technique earns its place in this list of prompt engineering examples due to its innovative approach to complex problem-solving and its potential to unlock more sophisticated applications of LLMs. It was popularized by researchers at Princeton University and Google in their 2022 paper "ReAct: Synergizing Reasoning and Acting in Language Models," and further development and application continue within the AI alignment research community. While no specific website link is available for the ReAct framework itself, researching the paper will provide more in-depth information.
6. Output Format Control Prompt
Output Format Control prompts are a powerful technique in prompt engineering, enabling you to dictate the precise structure and format of the AI's response. Instead of receiving a paragraph of text, you can instruct the AI to output data in JSON, CSV, markdown tables, HTML, or other specified formats. This makes these prompts invaluable for tasks requiring structured data, seamless integration with other software, and automated workflows. This approach is especially relevant for prompt engineering examples because it demonstrates the level of control you can exert over large language models, moving beyond simple question-answering to complex data manipulation and generation.
These prompts work by including explicit instructions about the desired format within the prompt itself. Often, this involves providing a template or example of the desired structure, specifying field names, data types, and even nesting relationships within the data. For example, you could provide a JSON template with placeholders for the AI to fill, ensuring the output is perfectly formatted for your application. This level of control is what sets Output Format Control Prompts apart and earns them a place on this list.
Features:
- Contains explicit format specifications (JSON, CSV, markdown, etc.)
- Often includes a template or example of the desired structure
- May specify field names, data types, and nesting relationships
- Can include validation requirements or constraints
Pros:
- Ensures machine-readable or consistently formatted outputs
- Facilitates direct integration with other software systems
- Reduces post-processing needs
- Improves consistency across multiple generations
Cons:
- Models may occasionally break format despite instructions
- Complex formats can lead to syntax errors
- May constrain the AI's ability to provide nuanced information
Examples of Successful Implementation:
- API Development: Imagine building an API that requires JSON responses. An Output Format Control Prompt can ensure the AI consistently generates the correct JSON structure, simplifying integration.
- Data Analysis: Requesting data analysis results in a markdown table allows for easy visualization and sharing.
- Content Generation: Generate structured content like HTML or XML directly, eliminating the need for manual formatting.
Actionable Tips for Using Output Format Control Prompts:
- Provide a clear example: Show the AI exactly what you want the output to look like.
- Use delimiters: Triple backticks () or other delimiters clearly mark format sections in your prompt.
- Break down complex formats: For intricate structures, decompose them into smaller, manageable components.
- Include validation rules: Specify constraints like "rating must be 1-5" to ensure data integrity.
- Encourage self-validation: Instruct the model to check its output against the provided format before finalizing.
When and Why to Use This Approach:
Use Output Format Control Prompts whenever you need structured output or when integrating the AI into automated workflows. This technique is crucial for:
- Data processing pipelines: Transforming and manipulating data efficiently.
- API interactions: Ensuring seamless communication between systems.
- Consistent documentation: Generating reports and other documents in a standardized format.
This method, popularized by figures like Simon Willison and fueled by resources like OpenAI's function calling documentation, has become indispensable for developers and AI professionals working with large language models. By mastering Output Format Control Prompts, you can unlock the full potential of LLMs for a wide range of practical applications.
7. Persona-Based Audience Targeting Prompt
This prompt engineering example focuses on crafting prompts that speak directly to a specific audience segment, much like creating targeted marketing campaigns. By incorporating detailed descriptions of your ideal user – their demographics, psychographics, and even their behavioral patterns – you can guide the AI to generate highly relevant and effective content. This approach is particularly valuable for prompt engineering examples related to marketing, education, and user experience (UX) design, making it a powerful tool for anyone working with AI text generation. This method deserves its place on this list because it significantly boosts the effectiveness of AI-generated content by focusing its output on the specific needs and preferences of a target audience.
How It Works:
Persona-based audience targeting prompts provide the AI with a rich understanding of the intended recipient of the content. Instead of just asking for generic text, you feed the AI specific details about your target persona. This includes demographic information (age, location, profession), psychographic insights (values, interests, lifestyle), and even behavioral characteristics (online habits, purchasing patterns). By painting this detailed picture, you enable the AI to generate content that resonates deeply with the specified audience.
Features:
- Detailed Demographics: Includes specifics like age, education level, occupation, and location.
- Psychographic Elements: Specifies values, interests, hobbies, pain points, and motivations.
- Behavioral Patterns: May include online habits, purchasing behavior, and content consumption preferences.
- Targeted Language: Often mentions specific language, jargon, or terminology that the audience commonly uses and understands.
Examples of Successful Implementation:
- Marketing: Crafting compelling ad copy for "tech-savvy millennials with sustainability concerns" by focusing on eco-friendly features and using modern, concise language.
- Education: Adapting educational materials for "middle school students with varying reading levels" by generating simplified explanations and incorporating engaging visuals.
- Healthcare: Generating clear and accessible healthcare information for "seniors with limited technical knowledge" by using plain language, avoiding jargon, and focusing on practical application.
Pros:
- Highly Relevant Content: Generates output tailored to the specific needs and interests of your audience.
- Improved Engagement: Content resonates more deeply, leading to increased interaction and conversion rates.
- Consistent Tone & Complexity: Maintains language and style appropriate for the target persona.
- Addresses Specific Needs: Allows you to focus on resolving particular concerns or answering specific questions relevant to the audience.
Cons:
- Potential for Stereotyping: Overgeneralized personas can lead to biased or stereotypical content.
- Requires Audience Research: Effective implementation requires thorough understanding of your target audience.
- Limited Accessibility: Hyper-focused content might exclude individuals outside the defined persona.
Actionable Tips:
- Research-Based Personas: Develop personas based on solid research, not assumptions.
- Focus on Goals and Motivations: Include information about what the audience wants to achieve, not just their demographics.
- Specify Existing Knowledge: Indicate the audience's prior understanding of the topic to avoid overly simplistic or overly complex explanations.
- Preferred Communication Styles: Note any preferred communication styles or vocabulary.
- Address Objections: Consider including potential audience objections or concerns to be addressed proactively.
When and Why to Use This Approach:
Use this prompt engineering technique whenever you need to generate content that resonates with a specific group. It's particularly effective for:
- Targeted Advertising: Creating compelling ad copy that speaks to the needs and desires of specific customer segments.
- Personalized Content Marketing: Developing content that attracts and engages specific buyer personas.
- Educational Material Development: Tailoring learning experiences for students with diverse backgrounds and learning styles.
- UX Design & User Research: Creating user-centered interfaces and experiences based on deep understanding of user needs.
Popularized By:
This approach has been embraced by content marketing strategists adapting persona techniques to AI, UX research practitioners incorporating AI into design processes, and marketing agencies developing AI-driven personalization systems. By leveraging the power of persona-based targeting, you can unlock the full potential of AI text generation and create content that truly connects with your audience.
8. Iterative Refinement Prompt
This prompt engineering example focuses on the Iterative Refinement Prompt, a powerful technique that treats prompting like a conversation. Instead of aiming for a perfect output on the first try, this method uses a series of prompts, with each one building upon and refining the previous AI-generated output. This approach is particularly effective for complex tasks and allows for a more nuanced and controlled output, making it a valuable tool in your prompt engineering arsenal. This is a crucial example of prompt engineering and thus deserves its place in any list of prompt engineering examples.
This process mirrors how humans collaborate creatively: you start with a general idea, receive feedback, make revisions, and progressively refine the work until it meets the desired outcome. It's a key technique for anyone working with Large Language Models (LLMs) and seeking to maximize their potential. Learn more about Iterative Refinement Prompt
How It Works:
- Initial Prompt: Start with a broader, more general prompt outlining the core requirements of your desired output.
- Feedback and Refinement: Review the AI's output and provide specific feedback on areas for improvement. Use phrases like "Improve this by..." or "Refine this draft with..." to guide the AI.
- Iteration: Submit a new prompt incorporating your feedback and any additional specifications. This new prompt uses the previous output as context.
- Repeat: Continue this cycle of feedback and refinement until the output meets your expectations.
Features of Iterative Refinement Prompts:
- Progressive Refinement: Begins with a general prompt and becomes increasingly specific in subsequent iterations.
- Feedback Integration: Incorporates explicit feedback on previous outputs to guide the AI.
- Directive Phrasing: Often includes phrases like "Improve this by..." or "Refine this draft with...".
- Evaluation Criteria: May include specific criteria for evaluating and improving the output.
Examples of Successful Implementation:
- Professional Writing: Writers use LLMs for drafting articles, blog posts, or marketing copy, refining the text through multiple iterations to achieve a polished final product.
- Software Development: Developers use iterative prompting to generate and refine code snippets, improving code quality and functionality step-by-step.
- Design Brief Development: Designers use this technique to refine design briefs, starting with general ideas and progressively adding detail and specifications through feedback loops with the LLM.
Pros:
- Higher Quality Results: Produces more refined and tailored outputs compared to single-prompt approaches.
- Manageable Complexity: Breaks down complex tasks into smaller, more manageable stages.
- Natural Creative Process: Mimics human collaborative workflows, fostering a more natural and intuitive interaction with the AI.
- Course Correction: Allows for adjustments and course correction throughout the process, minimizing the risk of off-target results.
Cons:
- Time-Consuming: Requires more time and effort compared to single-prompt methods.
- Increased Token Usage: Can lead to higher token usage and potentially increased costs.
- Active Engagement: Demands more active engagement and judgment from the user.
Tips for Effective Iterative Refinement:
- Start Broad, Get Specific: Begin with broader requirements and progressively refine them in later iterations.
- Actionable Feedback: Provide clear, specific, and actionable feedback instead of general criticism.
- Focus on Specific Aspects: Concentrate on improving one or two aspects in each iteration to avoid overwhelming the AI.
- Track Progress: Save intermediate outputs to monitor progress and revert to previous versions if necessary.
- Use Evaluation Criteria: Establish specific evaluation criteria to objectively assess improvements.
This approach, popularized by figures like Andy Matuschak and Ethan & Lilach Mollick, and embraced by writers like Simon Willison, is invaluable for AI professionals, software engineers, tech-savvy entrepreneurs, and anyone looking to leverage the full potential of LLMs like ChatGPT, Google Gemini, and Anthropic's models. By embracing iterative refinement, you can unlock higher quality outputs and navigate complex tasks with greater control and precision.
Prompt Engineering Techniques Comparisonmarkdown
| Technique | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Chain-of-Thought Prompt | Medium – requires structured reasoning instructions and examples | Higher token usage due to detailed steps | Improved accuracy on complex reasoning tasks; transparent logic | Mathematical problems, logical reasoning, multi-step analysis | Boosts accuracy; reveals reasoning; reduces hallucinations |
| Few-Shot Prompting Template | Low to Medium – provide several examples in prompt | Moderate token consumption from examples | Consistent, context-aware responses; better at nuanced tasks | Classification, translation, summarization, general tasks | Improves output consistency; reduces need for lengthy instructions |
| Role-Based Prompting Framework | Low – assign AI a specific persona or role | Low to moderate, depending on detail | Expert-like, focused, and relevant responses | Domain-specific queries, creative tasks, professional advice | Elicits domain knowledge; consistent tone; improves relevance |
| CRISPE Framework Prompt | High – involves multiple structured prompt elements | Higher due to detailed contextual inputs | Highly aligned, structured, and clear outputs | Marketing, education, business analysis, complex tasks | Reduces ambiguity; adaptable across domains; comprehensive |
| Zero-Shot ReAct Prompt | High – requires iterative Thought, Action, Observation cycles | High token usage from iterative steps | Enhanced multi-step reasoning and decision-making | Complex problem solving, information gathering, troubleshooting | Transparent reasoning; reduces hallucinations; iterative process |
| Output Format Control Prompt | Low to Medium – specify strict output format and templates | Moderate, depends on format complexity | Consistent, machine-readable outputs suitable for automation | API responses, data extraction, documentation generation | Ensures format compliance; reduces manual post-processing |
| Persona-Based Audience Targeting Prompt | Low – define detailed audience persona | Low to moderate depending on detail | Targeted, audience-specific content with relevant tone | Marketing, education, UX design, customer support | Increases relevance and engagement; tailored tone and style |
| Iterative Refinement Prompt | Medium to High – multiple rounds with feedback | Higher due to multiple prompt cycles | Progressive improvement in output quality | Writing, coding, design, creative development | Achieves better results; allows corrections; mimics collaboration |
Mastering Prompt Engineering with MultitaskAI
This article explored eight powerful prompt engineering examples, ranging from the Chain-of-Thought prompt and Few-Shot Prompting to the CRISPE Framework and Zero-Shot ReAct prompt. We also delved into techniques like Output Format Control, Persona-Based Audience Targeting, and Iterative Refinement, showcasing how these strategies can unlock the full potential of large language models (LLMs). By understanding and applying these diverse approaches, you can significantly improve the accuracy, relevance, and creativity of LLM outputs.
The key takeaway is that effective prompt engineering is not about simply asking a question; it's about crafting precise instructions that guide the LLM towards the desired outcome. Mastering these concepts empowers you to generate higher-quality content, automate complex tasks, and extract deeper insights from data. Whether you're a seasoned AI professional or just starting your journey with LLMs, these prompt engineering examples provide a solid foundation for building more effective and engaging AI interactions. As you integrate these techniques into your projects, remember that clean, well-structured code is essential for managing the complexities of AI development. For further guidance on structuring your code effectively for AI/ML projects, explore these comprehensive code structure best practices.
MultitaskAI offers an ideal environment to experiment with these prompt engineering examples. Features like split-screen comparisons, custom agents, and dynamic prompts allow you to refine your approach, compare different strategies, and ultimately, maximize your productivity when working with AI.
Start exploring the possibilities with MultitaskAI today and elevate your prompt engineering skills to the next level. The future of AI interaction is in your hands – craft it wisely.