How to Fine-Tune LLM: A Complete Guide for Success
Learn how to fine tune llm effectively with proven strategies from AI experts. Optimize your models and achieve better results today.
The Fine-Tuning Fundamentals You Need to Know
Fine-tuning a large language model (LLM) is like transforming a skilled generalist into a specialized expert. It builds upon the knowledge gained during pre-training, refining abilities for a specific task or area. This involves adjusting the model's parameters with a smaller, focused dataset, resulting in greater accuracy and reliability than using a generic model.
Why Fine-Tune an LLM?
The main benefit of fine-tuning is enhanced performance in niche areas. For example, a pre-trained LLM might generate general text well but struggle with medical terms. Fine-tuning with medical text data allows the LLM to understand and use this specialized vocabulary correctly. This precision goes beyond vocabulary:
Style and Tone Adjustment: Fine-tuning can tailor the LLM's output to a specific style, creating unique personalities for different applications. Need a formal chatbot? Or a playful one? Fine-tuning makes it possible.
Format Control: Fine-tuning trains the LLM to consistently output in a specific format, whether it’s JSON, YAML, or Markdown. This is essential for integrating LLMs into existing systems.
Handling Edge Cases: Pre-trained models have limitations. Fine-tuning helps LLMs handle unusual situations and reduce inaccuracies, leading to more reliable results, especially for complex applications.
Fine-tuning LLMs is vital for adapting pre-trained models to specific tasks. Using pre-trained models leverages existing knowledge, saving time and resources. Models like those from Meta and Google show improved efficiency, with smaller models sometimes outperforming larger ones. This boosts performance and lowers training costs by focusing on domain-specific details. Fine-tuning is crucial for high accuracy and reliability in specialized uses, surpassing prompting alone. Learn more about fine-tuning LLMs here: Fine-tune LLMs in 2025. You might also be interested in: How to Fine Tune LLM.
Fine-Tuning vs. Other Methods
Other techniques like prompt engineering and in-context learning can improve LLM performance, but they have limits. Prompt engineering relies on crafting precise instructions, which can be difficult and time-consuming. In-context learning uses examples within the prompt, but this becomes expensive with many examples. Fine-tuning offers a more robust and efficient way to specialize LLMs, improving accuracy and reliability. This makes it a better choice for adapting LLMs to specific domain requirements.
Preparing Your Data: The Make-or-Break Step
Fine-tuning a Large Language Model (LLM) is much like baking a cake. Even with the best recipe (model architecture), the final product hinges on the quality of the ingredients (data). This crucial data preparation stage can make or break your fine-tuning efforts. Investing time in creating high-quality data is essential; otherwise, your model's performance will suffer.
Data Collection: Getting the Right Ingredients
First, identify what you want your LLM to learn. Are you aiming for a specific tone of voice? Does your model need to master a particular format? Answering these questions clarifies the type of data you need. For example, to train a customer service chatbot, gather customer service transcripts. You might also consider supplementing with external sources, always prioritizing quality and relevance.
Data Cleaning: Refining the Mix
Raw data is often messy. Data cleaning removes noise, inconsistencies, and errors that can negatively impact LLM fine-tuning. This process might involve correcting spelling mistakes, removing duplicate entries, and standardizing formats. For example, ensure all dates follow the same format (YYYY-MM-DD). This pre-processing is vital for smooth and effective fine-tuning.
Data Formatting: Setting Up for Success
LLMs require specific input formats. Formatting your cleaned data ensures compatibility and optimizes training. This often means structuring data into input-output pairs. The input represents the task or prompt, while the output shows the desired response. This consistency is key to efficient learning.
Handling Data Challenges: Troubleshooting the Recipe
Common data preparation challenges include insufficient examples, domain-specific terminology, and maintaining consistent quality. If data is scarce, consider data augmentation techniques like rephrasing existing examples. For specialized vocabulary, create a glossary for your LLM. Maintaining consistency throughout your dataset is crucial for achieving optimal results.
The following table summarizes key steps and considerations for preparing your data for LLM fine-tuning:
Data Preparation Checklist for LLM Fine-Tuning Essential steps and considerations when preparing your dataset for fine-tuning
| Preparation Stage | Key Actions | Common Pitfalls | Quality Indicators |
|---|---|---|---|
| Data Collection | Define learning objectives, identify relevant sources, gather data | Insufficient data, irrelevant sources | Data relevance, source reliability |
| Data Cleaning | Correct errors, remove duplicates, standardize formats | Inconsistent cleaning, overlooking errors | Data accuracy, consistency |
| Data Formatting | Structure into input-output pairs, ensure LLM compatibility | Incorrect formatting, incompatibility with LLM | Consistent formatting, efficient parsing |
| Data Augmentation | Rephrase examples, use back translation, apply synonym replacement | Over-augmentation, introducing new errors | Increased data diversity, maintained quality |
This checklist helps ensure your data is well-prepared for fine-tuning, covering crucial steps from collection to augmentation. Addressing these points improves the chances of a successful fine-tuning process.
Balancing Quantity and Quality: The Perfect Recipe
While a large dataset is generally preferred, quality is paramount. A smaller, high-quality dataset often outperforms a vast, noisy one. Striking the right balance between quantity and quality ensures efficient and effective fine-tuning, maximizing your LLM's potential.
Data Augmentation: Stretching Your Ingredients
When working with limited data, data augmentation becomes invaluable. Techniques like back translation (translating text to another language and back) or synonym replacement create variations of existing data, effectively increasing the training set's size and diversity. By carefully enriching your dataset, you lay the foundation for a high-performing fine-tuned LLM. Successfully preparing your data is a critical step in fine-tuning an LLM.
Get started with your lifetime license
Enjoy unlimited conversations with MultitaskAI and unlock the full potential of cutting-edge language models—all with a one-time lifetime license.
Demo
Free
Try the full MultitaskAI experience with all features unlocked. Perfect for testing before you buy.
- Full feature access
- All AI model integrations
- Split-screen multitasking
- File uploads and parsing
- Custom agents and prompts
- Data is not saved between sessions
Lifetime License
Most Popular€99€149
One-time purchase for unlimited access, lifetime updates, and complete data control.
- Everything in Free
- Data persistence across sessions
- MultitaskAI Cloud sync
- Cross-device synchronization
- 5 device activations
- Lifetime updates
- Self-hosting option
- Priority support
Loved by users worldwide
See what our community says about their MultitaskAI experience.
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
Selecting Your Base Model: Making The Right Match
Choosing the right base model is the first crucial step in effectively fine-tuning a large language model (LLM). Think of it as the foundation of your specialized LLM. It greatly impacts the final performance. The number of available models is constantly growing, from open-source options like Llama and Mistral to commercial options from companies like OpenAI and Anthropic. Making the right match requires careful thought.
Evaluating Model Capabilities
Different models have different strengths. Some excel at creative writing, while others are better at analytical tasks. Think about what you want your fine-tuned LLM to do. If you want it to create imaginative content, pick a model known for its creativity. If your task needs accurate information retrieval, a model specializing in that would be a better fit.
Consider your specific goals.
Understanding Training Data Composition
The type of training data matters, too. If your data is very technical or specific to a certain field, a larger, more powerful model is likely necessary. This helps the model capture the nuances of your data. If your data is relatively simple, a smaller, more efficient model might be all you need. This could save computational resources and training time.
Think about your data’s complexity.
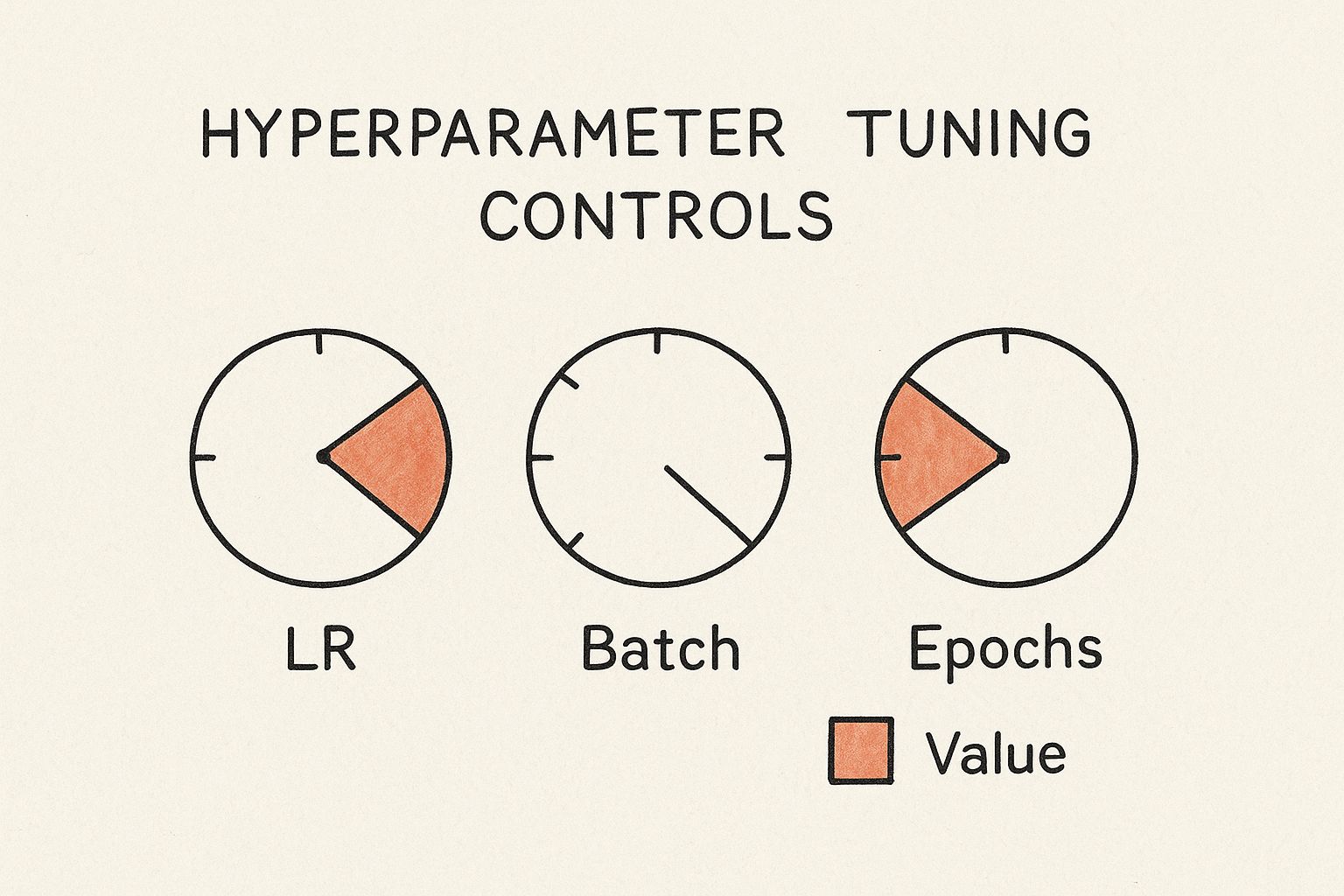
This infographic shows the process of hyperparameter tuning. The dials represent important parameters like learning rate (LR), batch size, and number of epochs. Finding the right balance for these settings is key for the best LLM performance.
Practical Considerations: Licensing, Cost, and Hardware
Beyond model capabilities, practical considerations are important, too. Licensing agreements can limit how you can use a model. Cost is another major factor. Some models require significant investment. Hardware requirements also vary. Complex models often need a lot of processing power. Think about these aspects before choosing your model.
Don’t forget the practicalities.
Large Vs. Small Models: Finding The Right Balance
There’s a trade-off between large and small models. Large models, with billions of parameters, have more potential for complex tasks but need substantial resources. Smaller models are more efficient but might not be suitable for highly specialized tasks. Your needs and resources will determine which size is best.
Balance performance with practical needs.
The following table summarizes key characteristics of popular base models to aid in your selection process:
Comparison of Popular Base Models for Fine-Tuning
| Model | Parameters | Open/Closed | Strengths | Limitations | Ideal Use Cases |
|---|---|---|---|---|---|
| Llama | 7B, 13B, 30B, 65B | Open | Strong performance on various tasks with relatively smaller model sizes. Cost-effective for fine-tuning and deployment. | Can be challenging to set up and optimize compared to commercial alternatives. | Research, experimentation, and applications where cost-effectiveness is a primary concern. |
| Mistral | 7B | Open | Designed for efficiency and performance. | Relatively new, so community support and resources are still developing. | Tasks where speed and efficiency are important. |
| OpenAI GPT models | Varies (e.g., 175B for GPT-3) | Closed | High performance on a wide range of tasks. Easy to use via API. | Can be expensive, especially for high-volume use. | Production-ready applications requiring robust performance. |
| Anthropic Claude | Varies | Closed | Focus on safety and helpfulness. Competitive performance. | Relatively less established compared to OpenAI. | Applications where safety and ethical considerations are paramount. |
Choosing a base model is like choosing the right tool for a job. Think about your goals, your data, and your resources. This strategic approach sets the stage for successful fine-tuning and determines how effective your custom LLM will be. By making the right choice, you'll get the best performance while using your resources wisely.
Fine-Tuning Techniques That Actually Work
Fine-tuning a large language model (LLM) involves more than just theory. It requires practical techniques for tangible results. This section explores approaches that balance performance gains with resource limitations, drawing on insights from ML engineers and real-world examples. We'll examine choosing between full fine-tuning and resource-efficient methods like LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA), honestly assessing the trade-offs.
Full Fine-Tuning: Maximum Control, Maximum Resources
Full fine-tuning adjusts all the parameters of the base model. This offers maximum control over the model's behavior and can significantly improve performance for your specific task. However, it’s also the most resource-intensive method. It's like renovating an entire house: complete design freedom but a substantial investment of time and materials. Full fine-tuning requires significant computational power, making it less accessible with limited GPU access or budget.
Parameter-Efficient Fine-Tuning (PEFT): Balancing Performance and Efficiency
PEFT methods, like LoRA and QLoRA, offer a more efficient alternative. Instead of modifying all parameters, they focus on a smaller subset. LoRA injects trainable rank decomposition matrices into the transformer architecture, efficiently adapting while keeping most model weights frozen. QLoRA quantizes the model's weights to 4-bit NormalFloat precision, drastically reducing memory requirements without sacrificing performance. It's like renovating just one room: significant improvements without a full overhaul's cost. These methods make fine-tuning more accessible with limited resources. You might be interested in: How to master prompt engineering and AI interactions.
Choosing the Right Technique
Choosing between full fine-tuning and PEFT depends on several factors:
Performance Requirements: If top-tier performance is critical and resources are available, full fine-tuning may be preferable.
Resource Constraints: PEFT techniques offer a practical approach for those with limited GPU access or budget.
Dataset Size: Smaller datasets may benefit from PEFT, while larger datasets might justify full fine-tuning.
When selecting a base model, consider upcoming trends. Read about key SaaS Trends to Watch When Selling Your Business.
Optimizing Hyperparameters and Preventing Catastrophic Forgetting
Optimizing hyperparameters like learning rate and batch size is crucial for successful fine-tuning, regardless of the chosen technique. Hyperparameters are like oven settings—adjusting them correctly ensures optimal results. Preventing catastrophic forgetting, where the model loses previously learned knowledge during fine-tuning, is also essential. Techniques like regularization can mitigate this, like reminding a baker of the basic recipe while teaching a new frosting technique.
Managing Training Time and Resources
Efficiently managing training time and resources is critical. Strategies like early stopping, halting training when the model stops improving on a validation set, can save resources. This is like checking a cake regularly and removing it when perfectly done, preventing overbaking.
Implementation Strategies and Code Examples
Implementing fine-tuning involves using frameworks like PyTorch or TensorFlow. We'll share implementation strategies using these frameworks, providing adaptable code examples. This empowers you to apply these techniques to your fine-tuning challenges. For example, leverage pre-built libraries and functions within these frameworks to streamline the process and manage resources.
Real-World Success Stories and Best Practices
Learning from successful teams is invaluable. We’ll explore how leading organizations optimize their fine-tuning workflows, implement effective stopping criteria, and prevent catastrophic forgetting. Understanding these real-world examples and best practices provides valuable insights and helps avoid common pitfalls. This collaborative knowledge sharing accelerates learning and fosters innovation within the LLM fine-tuning community. These tips and examples equip you to fine-tune LLMs effectively, maximizing performance while optimizing resources. Staying updated with the latest research in this evolving field is crucial for optimal outcomes.
Quantum-Enhanced Fine-Tuning: Breaking New Ground
Fine-tuning Large Language Models (LLMs) has traditionally relied on classical computing. However, a new approach is emerging: quantum-enhanced fine-tuning. This field combines classical and quantum computing to potentially unlock new levels of LLM performance. This opens exciting possibilities for training and optimizing these powerful models.
Hybrid Quantum-Classical Architectures
This advancement centers around hybrid quantum-classical architectures. These systems integrate classical computing methods, such as sentence transformers used in natural language processing, with quantum circuits. This combination allows researchers to approach LLM fine-tuning from a fresh perspective. Imagine using a quantum circuit to handle complex word relationships that are difficult for classical computers to grasp. This could lead to more accurate language understanding.
Quantum computing has recently entered the LLM fine-tuning field through these hybrid architectures. These models combine classical sentence transformers with quantum circuits to improve prediction accuracy. One study showed that adding quantum circuits can improve accuracy by up to 3.14% compared to similar classical models. This innovation could significantly improve LLMs' performance in complex tasks like sentiment prediction. Researchers are pushing the boundaries of AI by using quantum computing to optimize LLMs and enhance their performance. This marks a new frontier in integrating quantum technology with AI, potentially leading to breakthroughs in natural language processing and machine learning. Explore further: Quantum Computing and LLMs.
Current Implementations and Limitations
While still early, researchers are actively exploring quantum-enhanced fine-tuning. Some are using quantum computers to speed up parts of the training process, while others are developing new quantum algorithms for optimizing LLM parameters. However, there are limitations. Quantum computers are still relatively small and error-prone, restricting the size and complexity of LLMs that can currently benefit from quantum enhancement. Widespread use of these techniques is still in the future.
The Future of Quantum-Enhanced Fine-Tuning
Despite current limitations, the potential of quantum-enhanced fine-tuning is significant. As quantum hardware and algorithms improve, we can expect major advancements. Imagine LLMs that understand and generate human language with greater accuracy and fluency. This could revolutionize fields like machine translation, content creation, and even scientific discovery.
Early Adopters and Competitive Advantages
Forward-thinking organizations are already exploring how quantum approaches can give them a competitive edge with LLMs. By investing in this technology now, they are positioning themselves to be leaders in the next generation of AI. This proactive approach could lead to breakthroughs in specific industries and create entirely new markets.
Quantum-enhanced fine-tuning represents a major shift in how we optimize LLMs. While challenges remain, the potential for improvement in LLM performance makes this an area to watch. As quantum technology advances, this approach promises to unlock the full potential of LLMs, transforming how we interact with and benefit from artificial intelligence.
No spam, no nonsense. Pinky promise.
Measuring Success: Beyond Basic Metrics
Fine-tuning a Large Language Model (LLM) is a journey, not a destination. It's an iterative process, and to know if your efforts are making a difference, you need a solid evaluation framework. Simple metrics aren't enough. You need to look at both quantitative measurements and qualitative assessments for a complete picture of your model's performance.
Designing Effective Evaluation Datasets
A crucial part of measuring success is creating evaluation datasets that are up to the task. These datasets should mirror the real-world scenarios you expect your LLM to handle. For instance, if you're fine-tuning an LLM for medical diagnosis, your evaluation dataset should include a wide range of medical cases, from common ailments to rare diseases and intricate patient histories. This helps ensure your model is prepared for the complexities of real-world use.
Quantitative Measurements: Measuring Progress
There are several quantitative metrics that can help you track your fine-tuning progress:
Accuracy: This measures how often the LLM gets it right. It's a basic but essential metric.
Precision and Recall: These metrics provide a more detailed view. Precision looks at how many of the identified positive cases are actually correct. Recall looks at how many of the actual positive cases were correctly identified. These are particularly helpful when you're working with datasets where some categories are much more common than others.
F1-Score: This combines precision and recall into one handy metric, giving you a balanced overview.
Perplexity: This measures how well the model predicts the next word in a sequence. A lower perplexity suggests a better grasp of language and context.
While these numbers offer a solid foundation, they don't tell the whole story.
Qualitative Assessments: Understanding the Nuances
Numbers are important, but qualitative assessments bring in the human element. They offer insights into areas like:
Factual Accuracy: Is the information the LLM provides actually true? This is critical for applications where misinformation could have serious consequences.
Hallucination Reduction: Has the fine-tuning helped reduce the LLM's tendency to make things up? This is key for building trust.
Alignment with Intended Values: Does the LLM's output reflect ethical guidelines and societal values? This becomes especially important when LLMs interact directly with users.
You might use human evaluators to assess things like clarity, coherence, and helpfulness of the LLM's responses. This adds depth and perspective that metrics alone can't capture.
Implementing Evaluation Frameworks
Putting these evaluation techniques into practice requires a structured approach. For automated testing, consider platforms like pytest that can compare LLM outputs against a gold standard dataset. For human evaluation, develop clear guidelines and provide training for your evaluators to maintain consistency. This combination of automated and human evaluation can uncover insights hidden from standard metrics.
Continuous Improvement through Feedback Loops
Leading organizations don't just evaluate; they use their findings to continuously improve their LLMs. This involves creating feedback loops where the evaluation results are fed back into the fine-tuning process. This cycle of refinement is crucial for maximizing the LLM’s potential.
Measuring success isn’t just about checking off a list of metrics. It’s about a comprehensive approach that blends quantitative measurements with nuanced qualitative assessments. By using effective evaluation datasets, robust frameworks, and continuous feedback loops, you can ensure your fine-tuning efforts translate to real-world LLM performance that meets your project’s goals. For a broader perspective on project assessment, consider resources on code quality metrics. For more information on deploying AI models, see this article on Deploying AI models.
From Lab to Production: Making Your Model Deliver
A perfectly fine-tuned Large Language Model (LLM) needs to be put to practical use. This section discusses how to go from experimentation to a real-world application and offers strategies for successful deployment.
Optimizing for Efficiency
Before deploying your LLM, it's important to optimize it for efficiency. This leads to faster processing and reduced costs. Here are a few techniques:
Model Compression: Techniques like pruning and knowledge distillation can shrink your model's size without significant performance loss. This means quicker processing and lower memory requirements.
Quantization: Converting the model's parameters to a lower precision (like from 32-bit to 8-bit) reduces the memory footprint and accelerates calculations. Methods like QLoRA are highly effective for this.
Optimization for Specific Hardware: Adapting your model to the target hardware, whether it's CPUs, GPUs, or specialized AI accelerators, ensures optimal performance.
Deployment Environments: From Cloud to Edge
The right deployment environment depends on your specific circumstances. Here's a breakdown:
Cloud-Based Solutions: Cloud platforms offer scalability and ease of management, enabling you to quickly deploy and scale your LLM. Cloud providers handle the infrastructure, letting you focus on the application.
On-Premises Deployment: Deploying on your own servers gives you maximum control and data privacy, but requires managing your own infrastructure.
Edge Implementations: Deploying on edge devices like smartphones and IoT devices allows for quick processing and offline capabilities, but these devices have limited resources.
For more information, check out this article on How to master deploying AI models.
Monitoring and Maintaining Performance
Once deployed, continuous monitoring is essential:
Performance Tracking: Keep track of key metrics like latency, throughput, and error rates to ensure your LLM performs as expected.
Drift Detection: Identify changes in data distribution that can impact the model's performance. This helps maintain accuracy over time.
Feedback Mechanisms: Gather user feedback to identify areas for improvement and retraining, keeping your LLM relevant and effective.
Updating and Governance
Your LLM requires ongoing maintenance. Consider the following:
Model Updating Strategies: Implement strategies to retrain and update your model with new data. This maintains accuracy and adapts the model to changing requirements.
Governance Considerations: Establish clear guidelines for responsible AI usage, addressing ethical implications and potential biases.
Version Control: Use version control to track changes, revert to earlier versions, and maintain a development history.
Successfully deploying your fine-tuned LLM involves careful planning, optimization, and continuous maintenance. Measuring success goes beyond basic metrics and includes ensuring good code quality metrics. By addressing these key considerations, your LLM can deliver value and remain effective and reliable over time. This proactive approach ensures its long-term impact and usefulness. Treating your model as a dynamic entity will allow it to continue learning, adapting, and providing valuable insights.