Top Examples of Prompting: Boost Your AI Skills
Discover proven examples of prompting that help you master AI interactions – learn simple to advanced techniques for crafting effective prompts.
Unleash the Power of Prompting
Want to effectively communicate with AI and control its output? This listicle covers eight powerful prompting techniques, from basic to advanced, that are crucial for maximizing your AI interactions. Learn Zero-Shot, Few-Shot, Chain-of-Thought, Role, ReAct, Self-Consistency, Tree of Thoughts (ToT), and Retrieval-Augmented Generation (RAG) prompting. Master these techniques to get the most out of large language models.
1. Zero-Shot Prompting
Zero-shot prompting is a straightforward technique in the world of prompt engineering where you ask an AI model to perform a task without giving it any examples of how it should be done. The model relies solely on its prior training data to interpret your request and generate a response. This method is a pure test of the model's inherent ability to understand instructions and produce suitable outputs without task-specific guidance. Think of it like asking a student a question they haven't specifically been taught the answer to, but which they should be able to figure out based on their general knowledge.

Zero-shot prompting distinguishes itself through its direct instruction-based approach and minimal setup. Key features include: no examples provided, relying entirely on the model's pre-existing knowledge, requiring minimal prompt engineering, and being quick to implement. This makes it an attractive option for quickly assessing a model's baseline capabilities. Learn more about Zero-Shot Prompting and delve deeper into its nuances.
For instance, you could ask a model to "Summarize this article about climate change," "Translate the following text from English to Spanish," "Write a poem about autumn," or even "Explain quantum computing to a 10-year-old." These are all examples of zero-shot prompts. They provide a direct instruction without any illustrative examples.
When and why should you use zero-shot prompting? This method is best suited for common or relatively straightforward tasks where the model's pre-training is likely to cover the necessary knowledge. It's a valuable time-saver when exploring a new model or quickly prototyping ideas. It also allows you to gauge the breadth and depth of a model's understanding without investing time in crafting intricate examples.
Pros:
- Simplicity and ease of use: Zero-shot prompting is incredibly straightforward to implement, requiring minimal effort.
- Minimal preparation: No need to gather or curate examples.
- Efficient for common tasks: Works well for tasks that fall within the model's general knowledge domain.
- Reveals baseline capabilities: Provides a quick assessment of a model's inherent understanding.
- Saves time: Streamlines the prompting process significantly.
Cons:
- Less effective for complex tasks: Struggles with nuanced or specialized requests.
- Potential for inconsistent results: Outputs can be unpredictable due to reliance on pre-training.
- Dependency on pre-training: Performance is directly tied to the quality and scope of the model's training data.
- Limited control over output: Less fine-grained control over the format and style of the response.
- Difficulty with nuanced instructions: May misinterpret subtle instructions or context.
Tips for Effective Zero-Shot Prompting:
- Be clear and specific in your instructions: Ambiguity can lead to unexpected results.
- Break complex tasks into simpler components: Instead of one large prompt, use a series of smaller, more manageable prompts.
- Specify the desired output format: Tell the model whether you want a paragraph, a list, a poem, etc.
- Use domain-specific terminology when appropriate: This helps the model understand the context better.
- Consider adding context when necessary: Provide background information to guide the model's response.
Zero-shot prompting deserves its place in every prompt engineer's toolkit due to its simplicity and efficiency. While it might not be suitable for all scenarios, it's an invaluable technique for quickly testing models, exploring new ideas, and handling common tasks with minimal effort. This method is particularly relevant for AI professionals, developers, and anyone working with LLMs, providing a quick and easy way to interact with these powerful tools.
Get started with your lifetime license
Enjoy unlimited conversations with MultitaskAI and unlock the full potential of cutting-edge language models—all with a one-time lifetime license.
Demo
Free
Try the full MultitaskAI experience with all features unlocked. Perfect for testing before you buy.
- Full feature access
- All AI model integrations
- Split-screen multitasking
- File uploads and parsing
- Custom agents and prompts
- Data is not saved between sessions
Lifetime License
Most Popular€99€149
One-time purchase for unlimited access, lifetime updates, and complete data control.
- Everything in Free
- Data persistence across sessions
- MultitaskAI Cloud sync
- Cross-device synchronization
- 5 device activations
- Lifetime updates
- Self-hosting option
- Priority support
Loved by users worldwide
See what our community says about their MultitaskAI experience.
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Finally found a ChatGPT alternative that actually respects my privacy. The split-screen feature is a game changer for comparing models.
Sarah
Been using this for months now. The fact that I only pay for what I use through my own API keys saves me so much money compared to subscriptions.
Marcus
The offline support is incredible. I can work on my AI projects even when my internet is spotty. Pure genius.
Elena
Love how I can upload files and create custom agents. Makes my workflow so much more efficient than basic chat interfaces.
David
Self-hosting this was easier than I expected. Now I have complete control over my data and conversations.
Rachel
The background processing feature lets me work on multiple conversations at once. No more waiting around for responses.
Alex
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Switched from ChatGPT Plus and haven't looked back. This gives me access to all the same models with way more features.
Maya
The sync across devices works flawlessly. I can start a conversation on my laptop and continue on my phone seamlessly.
James
As a developer, having all my chats, files, and agents organized in one place has transformed how I work with AI.
Sofia
The lifetime license was such a smart purchase. No more monthly fees, just pure productivity.
Ryan
Queue requests feature is brilliant. I can line up my questions and let the AI work through them while I focus on other tasks.
Lisa
Having access to Claude, GPT-4, and Gemini all in one interface is exactly what I needed for my research.
Mohamed
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
The file parsing capabilities saved me hours of work. Just drag and drop documents and the AI understands everything.
Emma
Dark mode, keyboard shortcuts, and the clean interface make this a joy to use daily.
Carlos
Fork conversations feature is perfect for exploring different ideas without losing my original train of thought.
Aisha
The custom agents with specific instructions have made my content creation process so much more streamlined.
Thomas
Best investment I've made for my AI workflow. The features here put other chat interfaces to shame.
Zoe
Privacy-first approach was exactly what I was looking for. My data stays mine.
Igor
The PWA works perfectly on mobile. I can access all my conversations even when I'm offline.
Priya
Support team is amazing. Quick responses and they actually listen to user feedback for improvements.
Nathan
2. Few-Shot Prompting
Few-shot prompting is a powerful technique for interacting with large language models (LLMs). Instead of simply giving the model a task, you provide it with a few examples of the desired input-output pattern. Think of it like showing a student a few worked examples before asking them to solve similar problems. By demonstrating the pattern through examples, you guide the model towards the specific format, style, and reasoning you're looking for, even for complex or ambiguous tasks. This method significantly improves performance compared to zero-shot prompting, where the model receives no examples.
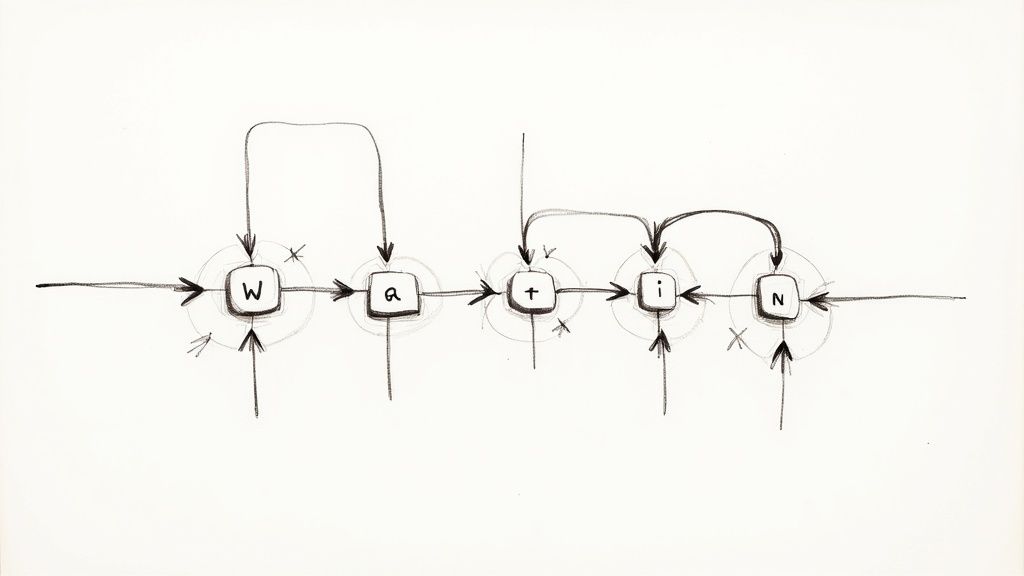
Few-shot prompting typically includes 2-5 examples of input-output pairs. This demonstration, rather than explicit instructions, helps the model understand the nuances of the task. Importantly, it works within the model's context window, meaning you don't need to fine-tune the model itself. This makes few-shot prompting a highly efficient and accessible technique. It allows you to specify format, style, and even reasoning patterns, making it invaluable for tasks requiring precise control over the output.
Examples of Successful Implementation:
Product Classification: Show the model a few examples of products and their corresponding categories (e.g., "iPhone 13 - Electronics", "War and Peace - Books"). Then, ask it to categorize a new product.
Custom Response Formats: If you need structured data, demonstrate the desired JSON format with a couple of examples. This guides the model to output results in the correct structure without explicit formatting instructions.
Sentiment Analysis: Provide examples of text snippets labeled with their sentiment (e.g., "This movie is amazing! - Positive", "I hated the ending. - Negative"). Then, provide new text for sentiment analysis.
Code Generation: Give examples of input requirements and the corresponding code that fulfills those requirements. Then, request new code based on a new set of input requirements.
Actionable Tips for Few-Shot Prompting:
Diverse Examples: Use a variety of examples that cover different aspects of the task, but keep them relevant to the overall objective.
Gradual Complexity: Order examples from simple to complex to facilitate learning.
Clear Demonstration: Make sure the examples clearly and unambiguously illustrate the pattern you want the model to follow.
Include Edge Cases: If handling unusual situations is important, incorporate examples demonstrating how to deal with these edge cases.
Explain Reasoning (for complex tasks): In more complex scenarios, consider explaining the reasoning behind the output in your examples. This can help the model understand the underlying logic.
When and Why to Use Few-Shot Prompting:
Few-shot prompting shines when dealing with complex or ambiguous tasks where zero-shot prompting falls short. It's beneficial when you require specific output formats, styles, or reasoning patterns. It’s particularly useful when you need consistent results and want to minimize the time spent iterating on prompts.
Pros:
- Improved performance compared to zero-shot prompting for complex tasks.
- Clarifies ambiguous instructions through demonstration.
- Provides consistent formatting and style guidance.
- Helps the model understand specialized domain knowledge.
- Reduces the need for extensive prompt iteration.
Cons:
- Requires more effort to craft than zero-shot prompts.
- Consumes more tokens than simpler approaches.
- Examples may introduce bias toward specific patterns.
- Still limited by the model's fundamental capabilities.
- Effectiveness depends on the quality and relevance of examples.
Few-shot prompting deserves its place in this list due to its effectiveness in guiding LLMs towards desired outcomes for complex tasks without the need for fine-tuning. Popularized by research from Google and OpenAI (specifically the GPT-3 paper "Language Models are Few-Shot Learners"), it has become a cornerstone technique for effective LLM interaction.
3. Chain-of-Thought Prompting
Chain-of-Thought (CoT) prompting is a powerful technique that enhances the reasoning abilities of large language models (LLMs). Instead of asking for a direct answer, CoT prompts guide the model to break down complex problems into smaller, more manageable steps, mimicking the way humans think through problems. This step-by-step reasoning process significantly improves the model's performance on tasks involving logical deduction, mathematical calculations, and analytical thinking. By explicitly modeling the logical flow, CoT helps prevent errors that might occur when the model attempts to jump directly to the solution.
One of the key features of CoT prompting is its ability to reveal the model's intermediate thinking. This transparency is invaluable for debugging and understanding how the model arrives at its conclusions. Furthermore, CoT is highly versatile and can be combined with both few-shot and zero-shot learning approaches. In few-shot learning, providing a few examples of step-by-step reasoning helps the model learn the desired pattern. Even without any examples (zero-shot), simply adding a phrase like "Let's think step by step" can often trigger the desired chain-of-thought behavior. This makes CoT particularly effective for a wide range of applications, from solving mathematical word problems and deciphering logical puzzles to complex decision-making and even code debugging. You can learn more about Chain-of-Thought Prompting and explore its potential in various scenarios.
For instance, consider the math problem: "36 students are going on a field trip. 9 parents volunteer to drive. Each parent's car can hold 4 students. How many more parents are needed for the trip? Let's think step by step." A CoT prompt would elicit a response like: "9 parents * 4 students/parent = 36 students can be driven. We need to transport 36 students / 4 students/parent = 9 parent drivers. Since we already have 9 parents, 9 - 9 = 0 more parents are needed." This clear breakdown not only provides the correct answer but also demonstrates the model's reasoning process. Other examples include using step-by-step deduction for logic puzzles, breaking down business decisions into evaluation criteria and analysis, and walking through code execution to identify bugs.
Pros:
- Dramatically improves accuracy on complex reasoning tasks.
- Makes the model's reasoning transparent and auditable.
- Reduces "hallucination" by enforcing step-by-step logic.
- Facilitates error detection in the reasoning process.
- Helps with tasks requiring multiple operations or calculations.
Cons:
- Consumes more tokens than direct responses.
- Can be overkill for simple tasks.
- May still propagate errors if early reasoning steps are flawed.
- Requires careful example selection for few-shot CoT.
- Can sometimes follow reasoning patterns too rigidly.
Tips for Effective CoT Prompting:
- Include phrases like "Let's think step by step" or "Reason through this" to trigger CoT behavior.
- For few-shot CoT, select examples with clear, concise, and correct reasoning.
- Balance detail with conciseness in the reasoning steps – avoid unnecessary verbosity.
- Use CoT especially when problems have potential calculation traps or require multi-step logic.
- Consider combining CoT with self-consistency techniques (generating multiple reasoning paths and selecting the most frequent answer) for even better results.
Chain-of-Thought prompting deserves its place in this list because it represents a significant advancement in prompting techniques. By encouraging models to think step-by-step, CoT unlocks their potential for complex reasoning and problem-solving, making them significantly more reliable and valuable tools across various domains. This approach is especially relevant for AI professionals, developers, and anyone working with LLMs who needs to ensure accuracy and understand the model's decision-making process.
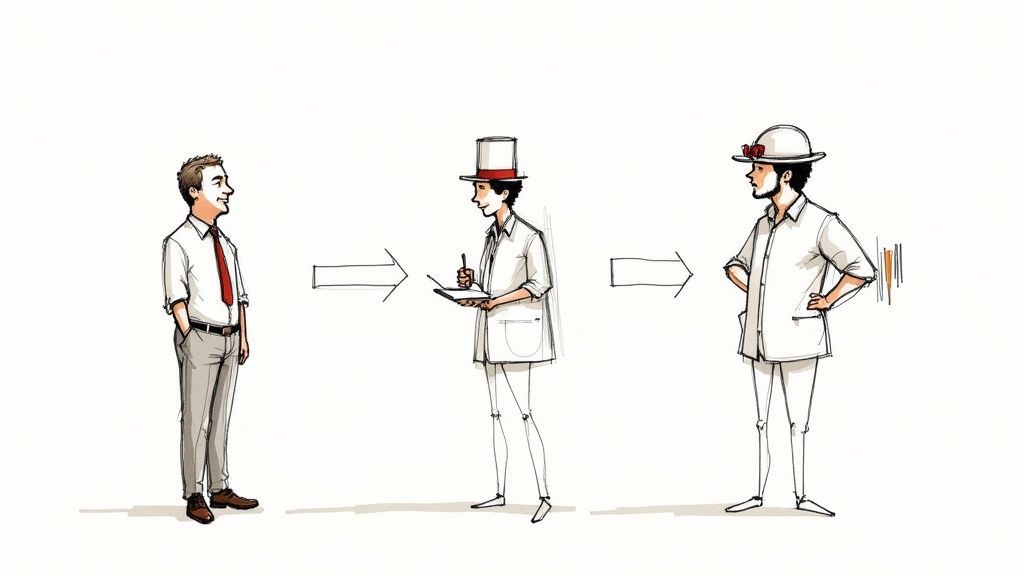
4. Role Prompting
Role prompting is a powerful technique that directs the AI to respond as if it were a specific character, professional, or entity. By assigning a role, you essentially give the AI a persona, influencing its tone, style, expertise, and overall approach to the prompt. This method leverages the AI's vast knowledge base to mimic how different individuals or experts would react or communicate in a given situation. Think of it as giving the AI a script and asking it to play a part. This allows you to finely tune the output to better suit your specific needs, whether you need a technical explanation from a data scientist, a creative story from a children's author, or a security audit from a cybersecurity expert.

Role prompting is especially valuable due to its ability to access domain-specific language and perspectives. It adds depth and richness to the AI's responses, making them more engaging and tailored to the intended audience. Features of role prompting include assigning a specific identity, defining the level of expertise, shaping the communication style and perspective, often starting with phrases like "Act as a..." or "You are a...", and potentially including detailed backstories or qualifications. You can even specify the intended audience to further refine the communication. For instance, asking the AI to "Act as a senior data scientist explaining correlation coefficients to a marketing team" will generate a different response than asking it to explain the same concept to a group of statisticians.
Examples of Successful Implementation:
- "Act as a senior data scientist explaining correlation coefficients to a marketing team."
- "You are a children's book author writing about photosynthesis for 7-year-olds."
- "Respond as Ernest Hemingway would write a short story about modern city life."
- "Take on the role of a cybersecurity expert conducting a security audit report."
Tips for Effective Role Prompting:
- Be Specific: Clearly define the role's expertise level, background, and the target audience. The more detail you provide, the better the AI can embody the role.
- Define the Goal: Specify the purpose of the communication. What do you want the AI to achieve in this role?
- Provide Tone Examples: Include examples of the desired tone or style to guide the AI's response.
- Prioritize Accuracy or Accessibility: For technical roles, clarify whether you need a highly accurate response or a more accessible explanation.
Pros:
- Stylistically consistent outputs
- Access to specialized knowledge and terminology
- Engaging and personalized content
- Maintained perspective in complex responses
- Ability to simplify or sophisticate explanations
Cons:
- Potential for overconfidence in specialized areas
- Risk of stereotypical or exaggerated portrayals
- Some roles might be rejected by AI safety systems
- Possible overemphasis on style over substance
- Effectiveness depends on the model's understanding of the role
Role prompting earns its place on this list because it fundamentally changes how you interact with the AI. It moves beyond simply asking for information and allows you to shape how that information is delivered. This is incredibly valuable for anyone working with AI, from developers creating interactive narratives to marketers crafting personalized content. You can learn more about Role Prompting and explore its diverse applications. Whether you're aiming for a specific writing style, a particular tone, or access to specialized knowledge, role prompting provides a versatile toolkit for enhancing AI interaction and maximizing the quality of generated content. This technique is especially beneficial for our target audience of AI professionals, software engineers, tech-savvy entrepreneurs, and various LLM users, empowering them to generate highly tailored and effective content.
No spam, no nonsense. Pinky promise.
5. ReAct Prompting
ReAct (Reasoning + Acting) prompting represents a significant advancement in how we interact with large language models (LLMs). It moves beyond simple question-and-answer interactions by enabling LLMs to actively engage with external resources and tools, making them far more powerful problem-solvers. Instead of passively generating text, ReAct prompts guide the model to perform a cycle of Thought, Action, and Observation. This allows the LLM to reason about a problem, take a specific action (like searching the web or using a calculator), observe the result, and then use that observation to inform further reasoning and actions.
How ReAct Works:
Imagine you're trying to find the current population of Tokyo. A standard prompt might simply ask "What is the population of Tokyo?". A ReAct prompt, however, would guide the LLM through a more structured process:
- Thought: "I need to find the current population of Tokyo. A reliable source would be a government website or a reputable statistical database."
- Action: "Search online for 'population of Tokyo'."
- Observation: "The top search result from worldpopulationreview.com states the population is 37.2 million as of 2023."
- Thought: "This seems like a credible source. I should report this figure."
This iterative process allows the LLM to dynamically adapt its approach based on the information it gathers, leading to more accurate and comprehensive results.
Examples of Successful Implementation:
ReAct prompting shines in scenarios that require external data or tool usage:
- Research tasks: "Find information about the history of AI, analyze the key milestones, and synthesize a timeline." The LLM could search Wikipedia, research papers, and other sources, synthesizing the information into a coherent timeline.
- Complex problem-solving: "Debug this Python code by examining the error message, testing hypotheses, and proposing fixes." The LLM could execute the code, analyze the error, search for solutions online, and propose code modifications.
- Decision-making scenarios: "Evaluate the best cloud platform for hosting a web application by researching AWS, Azure, and Google Cloud and comparing their features and pricing." The LLM can gather information on each platform and provide a comparative analysis.
- Information verification: "Fact-check this claim about the effects of caffeine by searching for reliable medical studies and analyzing the evidence." The LLM can consult medical databases and research papers to verify the claim.
Actionable Tips for Readers:
- Clearly define the available actions and their expected format: Tell the LLM what actions it can take (e.g., "search", "calculate", "access_database") and the expected format of the action and its output.
- Provide examples of good Thought → Action → Observation sequences: Demonstrate the desired interaction pattern with a few examples.
- Balance thoroughness with efficiency: Encourage the LLM to gather sufficient information without getting bogged down in unnecessary details or excessive searches.
- Set up guardrails to prevent infinite loops or rabbit holes: Limit the number of actions the LLM can take or define specific exit conditions.
- Consider implementing actual tool integration for production uses: Integrate with APIs and external tools to allow the LLM to interact with the real world.
When and Why to Use ReAct:
ReAct prompting is ideal for tasks that:
- Require access to external information or tools.
- Involve multi-step problem-solving or decision-making.
- Benefit from a transparent and traceable reasoning process.
- Demand high accuracy and grounded responses.
While simpler prompting techniques might suffice for straightforward questions, ReAct's power lies in its ability to tackle complex, real-world problems by combining reasoning with action.
Pros and Cons:
- Pros: Enables more complex problem-solving, reduces hallucination, makes reasoning transparent, facilitates multi-step tasks, improves planning and execution.
- Cons: More complex to implement, requires more resources, may need integration with external tools, can be overkill for simple tasks, potential for error propagation.
Popularized By:
Shunyu Yao, Jeffrey Zhao, Dian Yu, et al. in "ReAct: Synergizing Reasoning and Acting in Language Models" (2022), Anthropic and Google Research, LangChain framework implementations.
ReAct prompting deserves its place in this list because it represents a paradigm shift in LLM interaction, enabling a far richer and more powerful form of problem-solving. It unlocks the potential of LLMs to move beyond text generation and become active agents capable of interacting with the world around them.
6. Self-Consistency Prompting
Self-consistency prompting is a powerful technique for boosting the accuracy and reliability of large language models (LLMs). It works by asking the model the same question multiple times, independently, and then analyzing the different responses. Instead of relying on a single, potentially flawed chain of reasoning, self-consistency leverages the "wisdom of the crowd" by identifying the most frequent or consistent answer across multiple attempts. This approach is particularly effective for tasks with definitive or quantitative answers, where a clear "correct" solution exists.
How It Works:
Imagine asking an LLM a complex math problem. With standard prompting, the model might make a calculation error along the way, leading to an incorrect answer. Self-consistency prompting mitigates this risk by generating several independent solutions. If the model arrives at the same answer through different reasoning paths multiple times, that answer is more likely to be correct. This method is often combined with Chain-of-Thought (CoT) prompting to make the reasoning behind each solution transparent, further aiding in evaluating the reliability of the answers.
Examples of Successful Implementation:
- Mathematical problem-solving: Asking the model to solve a multi-step equation in several different ways and then selecting the most frequent result.
- Multi-step reasoning tasks: Presenting the model with a logic puzzle and having it generate multiple independent solutions, analyzing the commonalities in their reasoning paths.
- Code generation: Requesting different implementations of the same function and choosing the most efficient or elegant solution based on majority agreement.
- Translation validation: Translating a sentence into another language multiple times and selecting the most frequent translation to reduce the impact of individual errors.
Actionable Tips for Implementation:
- Generate a sufficient number of solutions: Aim for at least 5-7 independent responses for statistically reliable results.
- Encourage diverse reasoning paths: Use a temperature setting greater than 0 (e.g., 0.7) to introduce variability in the model's responses.
- Automate answer selection: Implement programmatic majority voting for objective questions where a clear "correct" answer exists.
- Consider weighted averaging: For more nuanced tasks, consider weighting answers based on the model's expressed confidence or the quality of its reasoning.
- Analyze divergent answers: Examine instances where the model provides significantly different answers to identify potential misconceptions or ambiguities in the prompt.
When and Why to Use Self-Consistency Prompting:
This technique is especially valuable when:
- Accuracy is paramount: For tasks where errors are costly, like mathematical calculations or logical reasoning.
- The problem has a definitive answer: Self-consistency works best when a clear "correct" solution exists.
- You want to increase confidence in the model's output: The consistency of responses provides a measure of confidence in the final answer.
- You want to identify potential biases: Divergent answers can reveal systematic biases in the model's reasoning.
Pros:
- Significantly improves accuracy, especially for math and logic problems.
- Reduces the impact of individual reasoning errors.
- Provides a measure of confidence through answer consistency.
- Explores diverse approaches to the same problem.
- Can identify when the model is uncertain (high variance in answers).
Cons:
- Increases computational cost due to multiple runs.
- More complex to implement in production systems.
- May still converge on incorrect answers if systematic biases exist.
- Less effective for subjective or creative tasks.
Popularized By:
Xuezhi Wang, Ian Covert, and others at Google Research, in their paper "Self-Consistency Improves Chain of Thought Reasoning in Language Models" (2022). The technique is also integral to Anthropic's Claude implementation.
Self-consistency prompting earns its place on this list because it offers a practical and effective way to enhance the reliability of LLMs, particularly for tasks demanding high accuracy and rigorous reasoning. By leveraging the power of multiple independent attempts and statistical aggregation, this technique addresses a key weakness of relying on single-shot prompting and provides a more robust approach to problem-solving with LLMs.
7. Tree of Thoughts (ToT) Prompting
Tree of Thoughts (ToT) prompting represents a significant advancement in leveraging large language models (LLMs) for complex problem-solving. Moving beyond the linear progression of Chain-of-Thought prompting, ToT explores multiple reasoning paths concurrently, much like a tree branching out with various possibilities. This allows the LLM to evaluate different approaches, backtrack from dead ends, and ultimately arrive at a more robust and well-reasoned solution. Think of it as giving the LLM the ability to brainstorm and strategize before committing to a single answer.
How It Works:
ToT prompting constructs a tree where each node represents a "thought" or intermediate step toward solving the problem. From each node, multiple branches emerge, representing different possible next steps or solutions. The LLM evaluates the "promise" of each branch using heuristics or evaluation criteria defined in the prompt. This allows it to prioritize more promising paths and prune less likely ones, effectively mimicking human strategic thinking. The exploration can be guided by either breadth-first search (exploring all branches at a given level first) or depth-first search (exploring one branch fully before moving to the next).
Examples of Successful Implementation:
- Game Playing: In games like chess, ToT can evaluate multiple potential moves and their downstream consequences, allowing the LLM to plan several steps ahead and choose the most strategic path. Imagine the LLM exploring sacrificing a pawn to gain a positional advantage - a decision requiring exploring branching possibilities.
- Creative Writing: ToT can help writers explore different plotlines, character arcs, or narrative twists. For instance, the prompt could ask for different endings to a story, and ToT could generate branches representing various scenarios, each evaluated for emotional impact or narrative coherence.
- Complex Problem-Solving: Mathematical proofs often involve exploring multiple approaches. ToT can guide the LLM to explore different theorems and lemmas, effectively creating a proof tree to arrive at the desired conclusion.
- Strategic Planning: Businesses face complex decisions with various potential outcomes. ToT allows LLMs to model these branching outcomes, evaluate their potential impact, and recommend the most promising strategies, considering potential risks and rewards.
Actionable Tips for Readers:
- Define Clear Evaluation Criteria: The success of ToT relies heavily on how effectively you guide the LLM to evaluate different branches. Specify clear heuristics or metrics within the prompt to assess the "promise" of each thought.
- Limit Exploration Depth: The computational cost of ToT can grow exponentially with the depth of the tree. Set limits on the number of levels the LLM should explore to manage complexity and token usage.
- Consider Beam Search: Beam search is a powerful technique to focus on the most promising paths. It keeps track of the top 'k' best paths at each level, discarding less promising options.
- Programmatic Implementation: Managing a Tree of Thoughts manually is extremely challenging. Leverage programming libraries and APIs to build a robust and scalable ToT implementation.
- Combine with Self-Consistency: At the final step, use self-consistency to evaluate the solutions produced by different branches and select the best overall solution.
When and Why to Use ToT Prompting:
ToT is particularly valuable when dealing with complex problems requiring strategic thinking, planning, and the ability to explore multiple possibilities. Use it when:
- Multiple solution paths exist: Problems with multiple valid approaches benefit from ToT's ability to explore and compare different options.
- Backtracking is necessary: When dead ends are likely, ToT's ability to revisit earlier decisions is crucial.
- Optimal solutions are hidden: For complex problems where the best solution is not immediately apparent, ToT can explore the solution space more thoroughly.
Pros:
- Superior performance on complex planning and reasoning tasks.
- Less likely to get stuck in local optima or dead ends.
- Provides multiple solution approaches for comparison.
- More closely mimics human strategic thinking.
- Allows for explicit uncertainty handling.
Cons:
- Significantly more complex to implement than other prompting techniques.
- Requires careful design of the thought exploration process.
- Consumes many more tokens than simpler approaches.
- Challenging to apply effectively without programming infrastructure.
- May be overkill for straightforward tasks.
Popularized By:
Yao et al. in "Tree of Thoughts: Deliberate Problem Solving with Large Language Models" (2023), Princeton University and Google DeepMind researchers. This technique is gaining traction within advanced AI research communities.
Tree of Thoughts prompting earns its place on this list because it represents a paradigm shift in how we interact with LLMs. It unlocks a new level of problem-solving capability, pushing the boundaries of what's possible with these powerful language models. While more complex to implement, the potential for solving intricate problems makes it a valuable tool for AI professionals and anyone seeking to leverage the full potential of LLMs.
8. Retrieval-Augmented Generation (RAG) Prompting
Retrieval-Augmented Generation (RAG) represents a significant advancement in prompting techniques. Instead of relying solely on a language model's internal knowledge, RAG empowers the model with access to external information sources, making it incredibly powerful for tasks requiring up-to-date, specific, or proprietary data. This approach combines the generative capabilities of large language models (LLMs) with the precision of information retrieval systems. Think of it as giving your LLM a research library and the ability to cite its sources.
How it Works:
RAG involves a two-step process. First, a user's query triggers a search through a designated knowledge base – this could be a vector database, a dedicated search engine, or even a collection of documents. The retrieval system identifies relevant information snippets based on the query. Second, these snippets are incorporated into the prompt given to the LLM. This enriched prompt provides context and grounds the LLM's response in specific, verifiable information. The LLM then generates its output, often including citations or references to the retrieved sources.
Examples of Successful Implementation:
- Customer Support Systems: Imagine a customer support chatbot that can instantly access product documentation and provide precise answers to technical questions, citing the relevant sections of the manual.
- Research Assistants: RAG enables research assistants to quickly synthesize information from recent academic papers, providing summaries and insights while citing the original sources.
- Legal AI Systems: Legal professionals can use RAG-powered systems to analyze cases, referencing specific laws and precedents retrieved from legal databases.
- Enterprise Knowledge Bases: Companies can leverage RAG to connect their internal documents to LLMs, enabling employees to easily access and utilize proprietary information.
When and Why to Use RAG:
RAG is particularly valuable when:
- Accuracy is paramount: Reducing hallucinations and ensuring factual accuracy is critical.
- Up-to-date information is needed: The task requires information beyond the LLM's training data cutoff.
- Specialized or proprietary data is involved: Accessing information not publicly available is necessary.
- Verifiability and source attribution are important: Citing sources and providing evidence for claims is required.
Tips for Effective RAG Prompting:
- Optimize Vector Embeddings: If using a vector database, ensure your embeddings effectively capture semantic meaning for accurate retrieval.
- Chunking Strategies: Break down documents into manageable chunks that balance context and retrieval precision. Too large, and you lose focus; too small, and you lose crucial context.
- Instruct to Cite Sources: Explicitly tell the LLM to cite the sources it uses in its response.
- Hybrid Retrieval Approaches: Combine keyword search with semantic search for more robust retrieval.
- Relevance Filtering: Implement filtering mechanisms to avoid overwhelming the LLM with too much information.
Pros:
- Significantly reduces hallucination and factual errors.
- Enables use of proprietary or specialized information.
- Provides current information beyond the model's training cutoff.
- Improves factual grounding and verifiability.
- Can handle domain-specific knowledge without fine-tuning.
Cons:
- Requires integration with retrieval systems, increasing complexity.
- Performance depends heavily on retrieval quality.
- May struggle with synthesizing contradictory information sources.
- More computationally expensive than standard prompting.
- Can increase latency due to retrieval operations.
Popularized By:
The concept of RAG has been significantly influenced by the work of Lewis et al. in their 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." Furthermore, organizations like Meta AI Research (formerly Facebook AI Research) have played a key role in its development. Frameworks like LangChain and LlamaIndex, along with vector database companies such as Pinecone and Weaviate, provide the tools and infrastructure for implementing RAG effectively.
RAG deserves its place in this list because it addresses a critical limitation of standard LLMs: their dependence on internal knowledge. By bridging the gap between generative AI and external information sources, RAG opens up a world of possibilities for building more accurate, informed, and powerful AI applications.
8-Point Prompting Comparison
| Technique | Complexity (🔄) | Resources (⚡) | Ideal Use Cases (💡) | Key Advantages (⭐) |
|---|---|---|---|---|
| Zero-Shot Prompting | Low – Minimal engineering | Low – Quick & lightweight | Straightforward tasks such as summarization or translation | Simplicity; reveals baseline model capabilities |
| Few-Shot Prompting | Moderate – Craft examples | Moderate – Extra tokens | Tasks needing clarity & format guidance; ambiguous cases | Improved performance; consistent output |
| Chain-of-Thought Prompting | Elevated – Step-by-step | High – More tokens needed | Multi-step reasoning like math, logic puzzles and analysis | Transparent reasoning; enhanced accuracy |
| Role Prompting | Low-Moderate – Framing role | Moderate – Context setup | Persona-based outputs; domain-specific explanations | Consistent tone; access to specialized knowledge |
| ReAct Prompting | High – Alternating steps | High – Complex cycles | Tasks that require reasoning plus actions (e.g., research) | Integrates action with thought; complex problem solving |
| Self-Consistency Prompting | Moderate-High – Multiple runs | High – Redundant processing | Definitive-answer tasks (math, logical problems) | Reduces errors through consensus; improves reliability |
| Tree of Thoughts (ToT) Prompting | Very High – Branch exploration | Very High – Intensive token use | Complex planning; strategic decision-making | Superior multi-path reasoning; robust exploration of options |
| Retrieval-Augmented Generation (RAG) Prompting | High – Retrieval integration | High – External system required | Knowledge-intensive tasks needing updated, verifiable data | Factual grounding; reduced hallucination |
Mastering AI with MultitaskAI
From zero-shot prompting to the intricate Tree of Thoughts, this article has explored a range of powerful techniques to enhance your interactions with AI models. The key takeaway is that prompting is not a one-size-fits-all approach; rather, it's about selecting and adapting the right technique for your specific needs. By understanding the strengths and weaknesses of each method, you can tailor your prompts to elicit more accurate, creative, and insightful responses. Mastering these concepts allows you to move beyond basic interactions and truly unlock the potential of large language models (LLMs).
While LLMs like ChatGPT excel at generating text from prompts, handling different data formats can be challenging. For example, working with PDFs often requires specialized tools and techniques. If you're interested in learning more about this, check out this resource on how can ChatGPT read a PDF. This guide explores the challenges and solutions for AI-powered PDF analysis.
The next step is to put these techniques into practice. Experiment with different prompting styles, analyze the results, and refine your approach. MultitaskAI offers the perfect platform to do just that. Its split-screen interface lets you compare prompts side-by-side, analyze their impact on AI-generated content, and connect directly to your API keys for seamless experimentation with leading AI models from OpenAI, Anthropic, and Google. Leverage the platform's features like custom agents and dynamic prompts to streamline your prompt engineering workflow. By combining the right techniques with the right tools, you can not only elevate your AI game but also unlock new levels of productivity and control in your AI journey. Start mastering the art of prompting today with MultitaskAI, and empower yourself to shape the future of AI interaction.